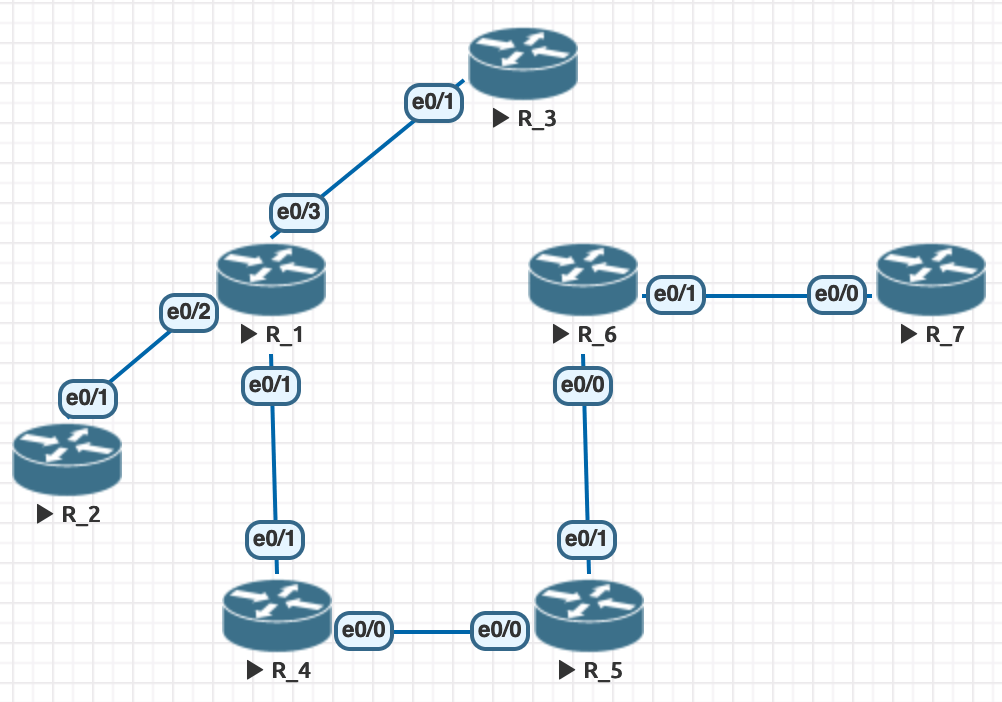
1.4.a Adjacencies
A quick review of everything we need to remember for adjacencies to form:
- Unlike EIGRP, the hello timer and dead timer in OSPF must match. Remember the dead timer is 4x the hello timer, not the typical 3x. We’ll probably be tasked with tweaking these in the lab.
- interface gig 0/0
- ip ospf hello-interval 1
- ip ospf dead-interval 3
- You need a router ID. For the lab we’ll be sure to manually configure this and not rely on an interface, especially considering we could be talking about routers that are only running IPv6.
- The have to be in the same subnet.
- Authentication has to match.
- interface gig 0/0
- ip ospf authentication message-digest
- ip ospf authentication-key C!sco123
- The area has to match.
- router ospf 1
- network 4.4.24.0 0.0.0.255 area 0
- Hand in hand with the area matching, the stub flag has to match, too.
- MTU has to match (by default, but this can be modified to be ignored.)
1.4.b Network types, area types
This seems like a good place for reviewing LSA types.
Type 1 – Router: There are two type 1 packets going around, one that shares the actual topology info, and one that validates point-to-point links. Why do we need to validate anything? R1 could be telling us about a route, but he could be a liar. Maybe he’s telling us about a loopback interface. But if R2 validates R1, then it’s more believable. R2 can say, “I vouch for R1, we’re connected on this link, he’s not lying.”
Type 2 – Network: These guys are sent from the DR and validate the other routers on that subnet. Similar to the secondary function of Type 1 LSAs, we need the DR to say, “I vouch for these knuckleheads, they’re with me,” referring to all the other routers on the DR’s segment.
Type 3 – Network Summary: This one comes from the ABR and summarizes the Type 1 and Type 2 LSAs to be sent to the neighboring area.
Type 4 – ASBR Summary: Also sent from the ABR, but it says, “Hey, I’ve got an ASBR here in my area. Here’s where you can find him.” So an ASBR Summary LSA only advertises a single /32 route, which tells other areas how to get to the ASBR.
Type 5 – AS External: OK, so Type 4 told us how to find the ASBR, but we still need the ASBR to tell us what he knows. That’s what Type 5 is used for, to tell the others about the redistributed routes learned from EIGRP, BGP, etc.
Type 7 – NSSA External: These are for our NSSAs. Since we can’t use Type 5 LSAs in the stub area, we need to disguise them as Type 7 LSAs. Then the ABR will make the switch to Type 5 LSAs when they leave the stub area.
Stub Areas
- Stub Area: Our regular Stub Area just blocks external routes, plus it injects a default route (as an IA route). So anything that was redistributed from EIGRP, etc. So that’s LSA type 5 that we’re blocking. And since we’re not sending Type 5 LSAs into the area, we don’t need Type 4 LSAs either, so we’ll just block them both. The default route is advertised using Type 3 LSAs.
- Totally Stubby: Totally Stubby is a subset of the Stub Area. It’s only applied on the ABR. The actual flag that determines if you’re able to make neighborships is the Stub Area flag. So Totally Stubby ABRs can neighbor with Stub Area routers. We’re going to block LSA type 5 (and 4) and (almost all) Type 3, and just inject the default route (so that’s just one IA route, but it is Type 3).
- Not-so-Stubby-Area: We want to be a Stub area and block external routes, but we’ve got an ASBR in our area. We need to make sure those external routes are able to get to the rest of our network. The NSSA ASBR makes those external routes LSA type 7, N2 routes. So Type 5 is still blocked, but Type 7 gets through. So we’re still blocking any external routes coming from another area, we’re just letting our own external routes get out of our area. One thing to note, we’re not injecting a default route with an NSSA, so we’ll lose connectivity to outside external routes.
- NSSA Stub Area: This one is a subset of the NSSA flag. All the routers in the area are still set the NSSA flag. The only difference is you add default-information-originate to the ABR, since the NSSA doesn’t inject the default route. Now it’s an NSSA Stub area so it does everything an NSSA does plus everything a Stub Area does.
- ABR Injects a default route.
- ABR blocks external routes from being sent into the NSSA Stub area.
- The internal ASBR that lives in the NSSA Stub area advertises his external routes as Type 7, N2 routes.
- The ABR flips those Type 7 to Type 5 on the way out of the NSSA Stub area into Area 0 (he also changes the source router-id to himself so people know how to get to these E2 routes, since we don’t have a Type 4 LSA to tell us.)
- router ospf 1
- area 10 nssa default-information-originate
- NSSA Totally Stubby Area: Same as an NSSA, we want do the whole LSA Type 7/Type 5 switcheroo, but we also want to block Type 3 LSAs.
1.4.c Path preference
Path Cost
Within an area, OSPF path preference is figured by just adding up the cost of the links to get to a destination. Cisco routers use 10^8/BW to calculate cost. !0^8 is the reference bandwidth. You can change this default reference bandwidth with:
auto-cost reference-bandwidth
Of course, as we saw with EIGRP, this default sucks in today’s day and age because anything over 100M is a cost of 1. We can also modify the cost on any given link.
interface gig 0/0
ip ospf cost 10
But between areas OSPF basically becomes a distance vector protocol. When an ABR sends the Network Summary LSAs which sum up the routes in Area 5 to a router in Area 0, the Area 0 router doesn’t bother with any SPF algorithms, it just adds the cost that the ABR is advertising plus the cost to get the ABR.
For instance, R3 is an ABR and has the 10.1.1.0/24 network in Area 10. He uses a Summary LSA to tell the routers in Area 0, “Hey guys, to get to the 10.1.1.0/24 network, come through me, the cost is 50.” Then R4 who is in Area 0 says to himself, “Well I know the cost to get to R3 is 30, so the cost to 10.1.1.0/24 must be 80.”
Routing Tables
One more thing I don’t want to forget, OSPF has two types of routes, regular network routes that you can view with show ip route ospf, but there’s also an ABR/ASBR routing table. This one tells you how to get to the router-id of an ABR, ASBR, or ABR/ASBR. To view this table it’s show ip ospf border-routers. This table also tells us whether it’s inter-area or intra-area, and it shows the next hop and the interface to use.
External Routes
Why are there two types of External Routes (E1 and E2)?
- E2 is the default and doesn’t bother with having a cost to get TO the ASBR, it’s only the cost that we configured during redistribution. The idea here is, “It doesn’t matter which path you take within our OSPF areas, what’s important is that you choose the ASBR that’s closest to the external route.” In other words, there’s no sense picking an ASBR that’s right next to us if that guy has to go around the world to get to the external network. We’re better off picking the ASBR that’s down the hall, since he’s got a really short path to the external network.”
- E1 is the opposite. E1 includes the local cost + the external redistribution cost. The idea here is similar to BGP. “Just get the traffic out of our OSPF AS as fast as possible, once it’s out of our OSPF areas, I don’t care what happens to it.” So now we’re going to find the shortest path inside OSPF to an exit point (ASBR).
Path Type
If all other things are equal, OSPF uses path type as a tie breaker. Intra-Area is the most preferred.
- Intra-Area
- Inter-Area
- E1
- E2
If the path type is the same, and the cost is the same, OSPF will load-balance up to 16 equal-cost paths. So key point here, if R1 can get to 10.1.1.0/24 with a cost 100 in the same area, and can get to 10.1.1.0/24 with a cost of 100 through an ABR to area 2, it won’t load balance. They’re not equal even though they have the same cost. If the cost through the ABR is 99, then that will be that path that gets chosen.
Rule #1, Most Precise Route Always Wins
All these things are nice, but we can’t forget that a /32 will always win over a /24. A /24 will beat a /23. Other factors only matter if both networks are exactly the same. We won’t consider path types, or routing protocol administrative distance unless the networks are exactly the same.
1.4.d Operations
1.4.d.i General Operations
The basic config of OSPFv2 is covered above, so I’ll just jump to OSPFv3 here.
OSPFv3
There are some changes made to LSA types from v2 to v3 to make OSPF run more efficiently (e.g. subnet changes aren’t advertised with Router and Network LSA’s, which would trigger an unnecessary SPF calculation, and instead are advertised with Type 9 LSA.) But for this post, I’m just going to focus on the configuration.
One thing worth noting is they added an Instance ID. The idea behind this is that you can have 4 routers on the same network segment, but run two separate OSPFv3 instances so they won’t all try to become neighbors. With OSPFv2 you’d have to use different authentication keys to keep them separate, but then you’re stuck with endless “key mismatch” logs on each router as they refuse to give up trying to form that neighborship. The instance ID must match for a neighborship to form.
R1
router ospfv3 1
router-id 0.0.0.1
interface gig 0/0
ipv6 address 2001:db8:0:44::1/64
ipv6 ospf 1 area 0 [instance 0]
R2
router ospfv3 1
router-id 0.0.0.2
interface gig 0/0
ipv6 address 2001:db8:0:44::2/64
ipv6 ospf 1 area 0 [instance ]
Note, leaving the instance keyword off is the same as setting it to instance 0.
1.4.d ii Graceful shutdown
You can either shut OSPF down globally or per interface. The idea here is that the neighbors get notified right away so you don’t have to wait for them to time out before the re-run their SPF algorithm.
Globally:
router ospf 1
shutdown
router ospfv3 1
shutdown
Per Interface:
interface gig 0/0
ip ospf shutdown
ipv6 ospf shutdown
1.4.d iii GTSM (Generic TTL Security Mechanism)
The idea here is that OSPF sets outgoing TTL on OSPF packets to 255, then sets a minimum TTL value that you’re willing to accept. So if I know all of my OSPF routers are just two hops away from each other, then I can set the max hops to 2. That way any incoming OSPF packets I receive from 3 hops or more away (so that 3-hop TTL is 253, as direct neighbors are 255, two hops are 254, etc.), I’ll drop them. It’s a little confusing. At first I thought the hop-count would be the actual TTL that you’d accept, but it’s not.
Another example, if you set the hop-count value to 254, then you’re basically not using this security mechanism anymore. So when you want to enable it on R1, but you haven’t enabled it on R2, you can set R1’s hop-count to 254, then jump over and enable it TTL Security on R2, then come back and set R1’s hop count back to 5 or whatever you want it to be.
Globally
R1
router ospf 1
ttl-security all-interfaces hops 8
Per Interface
R1
interface gig 0/0
ip ospf ttl-security hops 8
For IPv6 you can only configure TTL-Security for virtual-links and sham-links.
R1
router ospfv3 1
address-family ipv6
area 20 virtual-link 0.0.0.20 ttl-security hops 3
or
area 20 sham-link 2001:db8:10::A 2001:db8:20::D ttl-security hops 5